Faguke med SQL, DuckDB og forsinka tog
Visste du at du kan hente sanntidsdata om nesten alle norske kollektivreiser, helt gratis? Du trenger faktisk ikke en gang å lage en konto, eller skaffe API-nøkkel.
For en stund siden oppdaget jeg (Robin) sanntidsdatastrømmen til Entur. Jeg har tidligere lekt en del med store mengder historiske sanntidsdata for å studere forsinkelser i kart, men det er noe helt annet å kunne motta slike data live, bare sekunder etter avgang. En slik datastrøm har et skikkelig kult potensiale! Faktisk kom jeg på alt for mange idéer til ting jeg ville lage med en gang jeg så dataene. Det er synd jeg ikke har flere timer i døgnet! Heldigvis har vi faguka!
Faguka er en fest 🎉
Denne uken har vi hatt faguke i Amedia Produkt og Teknologi. Tre ganger i året har alle team i utviklingsmiljøet vårt en felles faguke. Dette er en anledning til å stoppe opp, ta en pause fra sprinting-en og fokusere på faglig kompetanseheving. Det fins ingen riktig eller feil måte å faguke på. Noen leser en bok. Noen deltar aktivt i det som organiseres av fellessesjoner der man jobber i gruppe på tvers av team rundt et tema. Noen lager seg en boble med et sideprosjekt som kan være helt eller delvis eller absolutt ikke relevant for jobben i det daglige.
Jeg (Elisabeth) vil lære å jobbe med data, analyse og SQL. Jeg har såvidt pirket i Postgres i en tidligere faguke. Stas! men det går… ganske… sakte… for meg å bygge kompetanse og få nok erfaring inn i fingrene til at det er klart for å overføre til virkeligheten på jobb. Men denne faguken har jeg hatt muligheten til å parprogrammere hele uken med ny makker (Robin) som tilfeldigvis har svart belte i SQL, et passelig stort datasett og et sideprosjekt med DuckDB og Rust som trampoline for å få fart. Kollektivtransport er ikke domenet vi sysler med til daglig. Det har vært interessant å se hvordan nettopp dét påvirker læring og fremdrift. Vi kan herje så veldig mye mer med et sideprosjekt der resultat og risiko ser helt annerledes ut enn rundt det vi har ansvar for på jobb.
Så da passet det kjempefint å dykke inn i kollektivtrafikkens verden! Men for å gjøre det, så må vi lære oss om SIRI.
Hva i alle verden er SIRI ET?
SIRI er en teknisk standard som spesifiserer utvekslingsformater for kollektivdata. SIRI ET handler om estimerte tidspunkt og reelle tidspunkt for stoppene. De fleste norske kollektivselskaper sender SIRI ET data til Entur, så da kan vi få alle datastrømmene fra ett enkelt API, i nær sanntid. Det som er veldig fint med denne datastrømmen er at den inkluderer både de oppsatte rutetidene, og de reelle tidspunktene. Så da kan vi få en datastrøm som gjør det enkelt å se hvor langt bak skjema bussen, toget eller ferja ligger.
Den enkleste måten å komme i gang med denne datastrømmen på, er å bruke SIRI Lite, og hente alle pågående og planlagte kollektivreiser som gjelder for omtrent nå, som XML eller JSON. Det gir oss faktisk skrekkelig mye data, nok til at båndbredde blir en begrensende faktor i hvor ofte vi kan oppdatere dataene våre. Men det er utrolig enkelt å komme i gang, bare se på dette:
curl -H 'accept: application/json' https://api.entur.io/realtime/v1/rest/et -o example.json
python -m json.tool example.json | less Hvis du foretrekker XML, så er det bare å fjerne accept-headeren og bestille seg time hos fastlegen med én gang. Det er veldig mye struktur i disse dataene, men det vi har kikket mest på er disse nodene:
EstimatedVehicleJourney- dette representerer én enkelt kollektivreise. Den har informasjon om hvilke linje reisen kjøres på, hvilket selskap som kjører den, hvilken type farkost det er, og mye mer.- En
EstimatedVehicleJourneyhar potensielt mangeEstimatedCalls. Dette er informasjon om planlagte stopp. Men bare de planlagte stoppene som reisen ikke har svippet innom fra før! For de er: RecordedCalls, som inneholder informasjon om oppsatt tidspunkt og faktisk tidspunkt. Som er akkurat det vi trenger for å kikke på forsinkelser!
Både RecordedCall og EstimatedCall har en referanse til et stoppested, i nasjonalt stoppestedsregister. Disse har Robin allerede hentet fra data.entur.org i forbindelse med at han har herjet med statistikk, men de kan også lastes ned fra denne siden. Vi trenger disse for å finne navnet til stoppestedene i SIRI ET-dataene, da de færreste vi kjenner, oss selv inkludert, klarer å lese stoppesteds-IDer. Det gir oss også noen spennende muligheter til å geolokalisere stoppene, og kanskje finne på noe kult med kart i fremtiden!
Fordi det er skikkelig tungt å hente absolutt alle dataene hver gang, så tillater SIRI Lite-apiet å sette en requestorId-parameter. Da får vi alle dataene første gang vi spør, og neste gang vi spør, så får vi bare endringer som har skjedd:
curl -H 'accept: application/json' 'https://api.entur.io/realtime/v1/rest/et?requestorId=31852a28-8615-422a-ac75-5ef4ca158233' -o example_full.json
sleep 10
curl -H 'accept: application/json' 'https://api.entur.io/realtime/v1/rest/et?requestorId=31852a28-8615-422a-ac75-5ef4ca158233' -o example_delta.json
# Mye mindre data i den andre filen! Luksus for json-parseren.
python -m json.tool example_delta.json | lessForsinka?
Vi bestemte oss for å hente dataene inn i DuckDB, for å kunne bruke en lynrask SQL-motor til å analysere dem. Så brukte vi masse tid på å studere disse dataene i DuckDB ui, og Elisabeth fikk brynet seg på å bruke joins, window functions, common table expressions, timestamp-problemer, coalesce, NULLs overalt og mye mer.
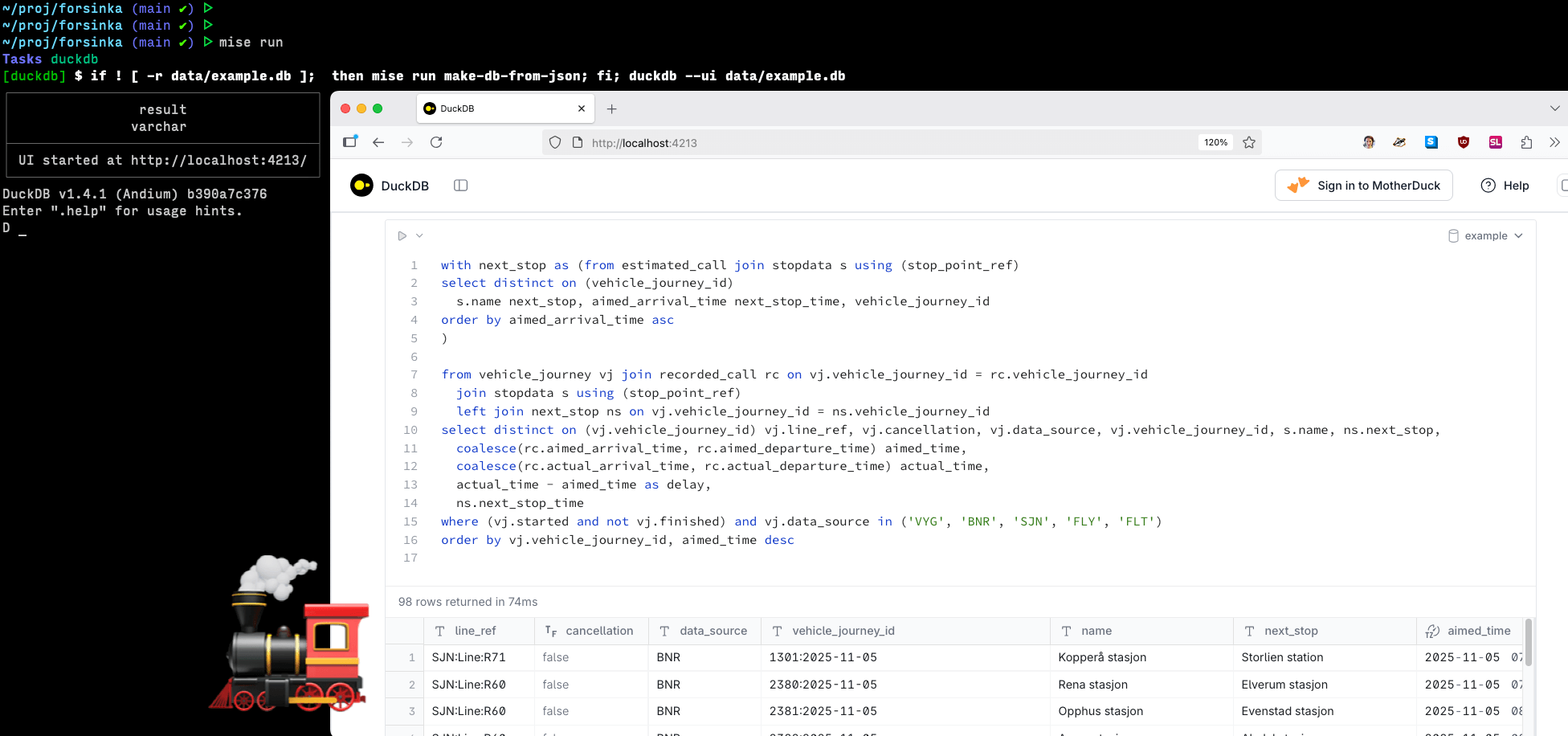
Etter ett par dager fikk vi opp en liten webapp som viser pågående togreiser på forsinka.kaveland.no. Her går det herlig fort å utvikle, siden vi kan deploye rett i produksjon for hver minste lille endring, helt uten testing. Deilig med faguke!
Denne faguken hadde et spor med temaet «lek og lær med KI». Vi glemte bort KI i mange dager, så vi kastet oss rundt på fredag for å få Claude Code til å generere hundrevis av linjer med HTML og CSS for oss. Vi valgte å beholde den ikoniske lilla KI-fargen for å hedre Claude for sitt bidrag. 💜
Webappen henter ned dataene fra SIRI ET ved oppstart; og så går den tilbake hvert 30. sekund for å få oppdateringer. Det er fascinerende å se hvor mange tog som kjører rundt i Norge i rushtiden, det var mange flere enn vi var klar over! Noen melkerute-linjer har 10 togsett gående samtidig. Skjønner ikke at vi har plass til alle disse togene! Hvor overnatter de?
Selv om webappen har mye mer data, så er det litt krevende å vise så mange pågående reiser på en god måte. Vi laget et API på /stop/{stop_name} som viser alle pågående reiser som skal innom et stoppested, og i skrivende stund så viser det 107 reiser som er på vei innom Jernbanetorget:
curl -s https://forsinka.kaveland.no/stop/Jernbanetorget | jq 'length'
107Det er ganske mye, ikke rart at ting kan stoppe opp når Oslo får første snøfall for sesongen. Her er det mange dekk som skal skiftes!
Hva har vi lært
- Det er faktisk temmelig komplisert å regne på forsinkelser.
- Det er ikke så vanskelig å lage webapper i Rust som man skulle tro 🦀
- Parprogrammering er stadig kjempemoro og utrolig lærerikt.
- Å bruke mise til å sette opp utviklingsmiljøet gjør det skikkelig lettvint for andre å komme i gang.
- Vi kan lære mye mer på én faguke enn vi rekker å skrive om!